innodb_purge_threads=1 ~ 32(기본 값: 1)
innoDB엔진에 생성된 테이블은 오라클과 비슷하게 undo 세그먼트를 사용한다. 버퍼 캐시의 변경된 내용은 주기적으로 디스크로 써야 하는데, 오라클의 경우 1개 이상의 DBWn라는 대몬이 전담하여 이를 처리하고 있는 것처럼 mariaDB도 디스크로 내려쓰는 역할을 전담하는 thread의 개수를 지정할 수 있다.
UNDO
innodb_undo_directory=경로(기본 값: .)
기본적으로 mariaDB에서 undo 영역은 시스템 테이블 스페이스의 일부 영역을 사용하고 있지만 별도의 테이블 스페이스 공간을 만들어 사용할 수도 있다. 점(.)은 버전 5.5 이전에서와 같이 시스템 테이블스페이스의 일부 영역을 사용하겠다는 의미이고, 다른 경로를 입력하면 undo 영역으로 사용할 테이블 스페이스 공간의 위치를 설정하게 된다. 보통 undo영역은 SSD와 같이 빠른 저장장치가 존재하는 위치로 지정하면 좋다.
innodb_undo_tablespaces=0 ~ 126(기본 값: 0)
하나의 undo 테이블스페이스 파일로 운영하면 경합이 발생할 수 있기 때문에 파일을 분할하여 부하가 분산될 수 있도록 한다. 이 파라미터로 지정한 값 만큼 innodb_undo_directory로 지정한 경로에 undoN (N은 숫자)로 undo 용 파일이 생성된다.
innodb_undo_logs=0 ~ 128(기본 값: 128)
하나의 언두 세그먼트에는 다수의 트랜잭션이 저장될 수 있다. innoDB에서는 하나의 언두 세그먼트당 최대 1023개의 트랜잭션이 저장될 수 있다. 이 파라미터는 세그먼트의 개수를 지정하는 것으로 최대innodb_undo_logs * 1023 개의 트랜잭션이 실행될 수 있는 것이다. 이 값은 늘리 수만 있고 줄일 수는 없으므로 처음부터 너무 큰 값을 주지 않도록 한다.
Buffer Pool
innodb_buffer_pool_populate=ON or OFF (기본 값: OFF)
리눅스에서는 사용자가 지정한 버퍼 풀 사이즈를 처음부터 모두 할당하지 않는다. 버퍼 풀 사용량이 늘어나면서 차츰 늘려주는 방식인데, 이로 인해 실제 메모리가 얼마나 할당되었는지 모니터링 하기 쉽지가 않고 잘못된 메모리 할당으로 인한 부작용이 종종 있어왔다. 따라서 버퍼 풀 사이즈를 DB 기동시부터 모두 할당받을 수 있는 기능을 제공한다. 이 값을 ON으로 하면 된다.
innodb_buffer_pool_load_at_startup=0 or 1 (기본 값: 0)
MariaDB를 재시작하면 버퍼캐시가 비게 되는데, 이 상태에서 서비스를 재개하면 Disk read가 심해지면서 부하가 심해질 수 있다. 이를 방지하기 위해 버퍼 캐시의 내용을 파일로 저장했다가 재기동시 읽어들여 버퍼 캐시를 복구하도록 할 수 있다(오라클에는 없는 신박한 기능인듯)
이 기능을 사용하려면 innodb_buffer_pool_dump_at_shutdown 파라미터에 의해 서버를 내릴 때 dump를 떨구도록 해야 한다.
innodb_buffer_pool_dump_at_shutdown=0 or 1(기본 값: 0)
MariaDB 를 내릴 때 버퍼캐시의 내용을 파일로 떨구도록 한다. innodb_buffer_pool_load_at_startup파라미터와 함께 쓰도록 한다.
innodb_blocking_buffer_pool_restore=0 or 1(기본 값: 0)
Dump로 버퍼 캐시의 데이터를 파일로 떨군 후 mariaDB 재기동 하면서 버퍼 캐시를 복구하는 도중에 XtraDB 스토리지 엔진을 참조하는 사용자 쿼리가 수행되면 복구작업이 늦어질 수 있다. 따라서 이 파라미터를 통해 쿼리 수행을 허용할 수 있을지 없을지를 결정한다. 1이면 블로킹한다.
innodb_buffer_pool_dump_now=0 or 1(기본 값: 0)
위에 언급한 innodb_buffer_pool_dump_at_shutdown 파라미터는 mariaDB를 내릴 때 dump 하는 것이지만 이 파라미터는 값을 1로 변경하는 순간 dump를 뜬다. 덤프가 완료되면 값이 다시 0으로 바뀐다.
innodb_buffer_pool_load_now=0 or 1(기본 값: 0)
innodb_buffer_pool_dump_now 파라미터와 비슷하게 이 파라미터는 값을 1로 변경하는 순간 dump파일에 있는 내용으로 버퍼 캐시를 복구한다. 완료되면 값이 다시 0으로 변경된다.
innodb_buffer_pool_load_abort=0 or 1(기본 값: 0)
innodb_buffer_pool_load_now에 의해 페이지를 버퍼 캐시에 로딩중 예상보다 시간이 오래 걸려 중지해야 할 경우 이 파라미터로 작업을 중지시킬 수 있다. 값을 1로 변경하는 순간 작업이 중지되며 파타미터 값도 다시 0으로 돌아온다.
innodb_flush_method= ‘O_DSYNC’ | ‘O_DIRECT’ | ‘O_DIRECT_NO_FSYNC’ | ‘ALL_O_DIRECT’ (기본 값: null)
기본적으로 리눅스 환경에서는 페이지를 버퍼캐시로 로드할 때 서버의 메모리로 올린 후 DB의 버퍼 캐시로 적재하게 된다. 이 과정에서 서버의 메모리와 DB의 버퍼 캐시가 동일한 페이지를 보관함으로써 더블 버퍼링이라고 하는 비효율성이 발생하게 된다. 따라서 서버의 캐시를 거치지 않고 바로 Disk로 write하거나 Disk로부터 바로 버퍼캐시로 read할 수 있도록 옵션을 제공하고 있다.
아래는 파라미터 값 별로 어떻게 동작하는지를 정리한 표이다.
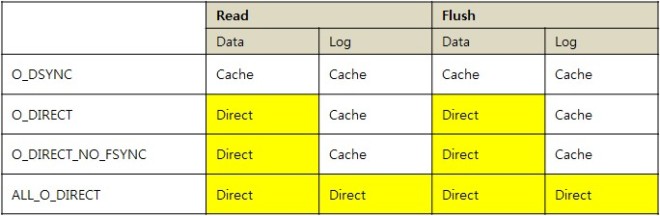
Read란 Disk에서 페이지를 읽어 버퍼 캐시에 적재하는 상황을 의미하며, Flush란LRU 및 더티 페이지 write, 체크포인트에 의해 write이 발생했을 때를 의미한다.
O_DSYNC는 서버의 data/log에 상관없이, 그리고 read/flush에 상관없이 항상 메모리를 거쳐가며 O_DIRECT는 Data에 대해서만 메모리를 거치지 않고 direct로 I/O를 수행하게 된다.
O_DIRECT_NO_FSYNC는 O_DIRECT와 비슷하지만 OS 내부적으로 fsync() 시스템 콜을 발행하지 않고 연기하는 메커니즘을 가지고 있다.
ALL_O_DIRECT는 data/log에 상관없이 항상 메모리를 거치지 않고 disk로 바로 I/O하도록 한다.
innodb_read_ahead_threshold=0~64 (기본 값: 56)
mariaDB는 오라클과 비슷하게 테이블 Full 스캔시 MBRC(Multi block Read Count)로 정의된, 여러 블록을 한꺼번에 읽는 방식이 존재한다. 그러나 오라클에서는 세션이 쿼리문을 보고 disk에서 멀티 블록을 읽어들인 후 가공하여 클라이언트에 반환하기 때문에 sync방식으로 처리된다. 하지만 mariaDB에서는 sync 방식으로 처리되지 않고 백그라운드에 의해 미리미리 멀티 블록을 읽어 적재하는 방식을 사용하고 있다. 이 때 최소 몇 개의 블록을 읽어 적재할 것인지를 설정하는 파라미터가 이것이다. 단위는 페이지의 개수이다.
Buffer Pool – Flush
update/Delete/Insert 등의 DML 작업으로 인해 값이 변경되었지만 아직 Disk로 write 되지 않은 블록이 버퍼 풀 내에 존재할 수 있다. 오라클의 경우 기본적으로 fast commit 매커니즘이라하여 사용자가 commit을 하면 redo file에만 기록을 하고 즉시 디스크로 sync하지 않는다. 대신 redo group change가 발생하면 체크 포인트가 발행되어 디스크로 일괄 write하는 매커니즘을 가지고 있다. 그러나 MariaDB는 오라클과 같이 redo file change로 인한 체크포인트가 발행되지 않는다. MariaDB는 여러 개의 redo file을 논리적으로 하나의 파일로 관리하며 redo group이 변경되었다고 체크포인트를 발행하지도 않는다. 그러나 지속적인 로그를 쌓기 위해선 redo file 도 정리하고 그 전에 버퍼 내용도 디스크로 flush하는 작업이 필요할텐데 언제 어떻게 할까?
어떻게 하긴.. 오라클처럼 명시적인 체크포인트가 따로 없으므로 평상시 지속적으로 버퍼를 flush하고 redo file을 정리해주어야 겠다. 이를 위해 몇 가지 파라미터를 제공한다. 버전 5.5 이전에서는 버퍼 풀을 보고 free공간이 없으면 LRU알고리즘을 통해 flush 하는 것을 사용자 스레드가 담당했었다. 그러나 5.6 버전부터는 백그라운드 스레드에 의해 flush하고 있다.
innodb_max_dirty_pages_pct=0~99.999 (기본 값: 75)
버퍼 풀에서 더티 페이지를 몇 프로까지 허용할 수 있을지 결정한다. 이 비율을 넘어가면 innodb_io_capacity 파라미터로 정한 값 만큼 한번에 페이지를 flush시킨다.
이 값을 낮추면 좀 더 자주 더티 페이지를 flush해주겠지만 버퍼 풀의 효율성이 떨어지게 되어 Disk I/O가 높아줄 수도 있다. 반면 너무 높으면 redo file에 더티 페이지가 꽉 차게 되고 더 이상 로그를 기록할 수 없는 지경에 이르게 될 수 있다. (mariaDB내에서는 redo file에 dirty 페이지가 얼마나 쌓였는지를 기록하고 있으며 그 비율에 따라 DB를 비상운용하게 된다)
innodb_io_capacity=100 ~ 2^64-1 (기본 값: 200)
innodb_max_dirty_pages_pct 파라미터로 명시한 값 만큼 버퍼 풀 내 dirty 페이지가 늘어나면 이 파라미터 값 만큼 한번에 페이지를 flush 시킨다. 보통 이 값은 서브디스크의 IOPS만큼 설정해주면 좋다. 예를 들어 IOPS가 200인 디스크가 Raid 1+0으로 4개로 묶여있다면 IOPS성능이 400이기 때문에 이 파라미터의 값도 400정도로 하면 좋다.
innodb_io_capacity_max=100 ~ 2^64-1 (기본 값: 2000)
innodb_io_capacity 파라미터에 설정된 만큼 페이지들을 flush 하는데도 dirty 페이지가 많이 생기면 이 파라미터에 명시된 값 만큼 페이지들을 공격적으로 flush한다. 너무 큰 값을 설정하면 I/O에 모든 자원을 소모시켜 문제가 될 수 있으니 적당히 높은 값으로 설정하도록 한다.
innodb_old_blocks_pct=5 or 95 (기본 값: 37)
버퍼 캐시에 존재하는 페이지의 LRU 리스트를 작성할 때 MRU(Most Recently Used) 부분과 LRU(Least recently used) 부분으로 나뉘는데 이 중 LRU의 비중을 몇 퍼센트로 할지를 정하는 파라미터이다. 기본 값인 37을 예로 들어보자. 이것은 버퍼 캐시에 존재하는 모든 페이지를 최근 사용한 순서로 나열했을 때 하위 37%에 해당하는 페이지들이 LRU 대상이라는 뜻이다.
리두로그
MariaDB에서는 오라클에서의 리두로그와 같은 역할을 하는 로그를 WAL(Write ahead log)라고 부르며 사이즈와 파일의 개수 및 위치를 모두 파라미터로 정의한다.
innodb_log_file_size = 108576(106KB) ~ 4294967295(4096MB) (기본 값: 50331648)
로그 파일의 사이즈를 결정하는 파라미터이며 기본 값은 48M이며 최대 4G까지 지정할 수 있다.
innodb_log_file_in_group = 2~100 (기본 값: 2)
로그 파일의 개수를 몇 개로 할 것인지를 결정하는 파라미터로 기본 값은 2이다. 파일명은 ib_logfileN (N은 숫자)로 지정된다.
innodb_log_group_home_dir = 경로 (기본 값: ./)
로그 파일이 위치할 경로를 결정하는 파라미터이며 디폴트 값은 ${HOME}/data 디렉토리이다.
innodb_log_archive=ON or OFF (기본 값: OFF)
기본적으로 아카이빙은 OFF되어 있다. ON하면 innodb_log_arch_dir 디렉토리에 저장하게 된다.
innodb_log_arch_dir= 경로 (기본 값: ./)
아카이브 파일의 저장 위치에 대한 파라미터이며 값을 설정하지 않으면 ${HOME} 디렉토리에 생성된다.
innodb_log_arch_expire_sec= (기본 값: 0)
아카이브 파일이 자동적으로 삭제되도록 타이머를 설정할 수 있다. 초 단위로 입력하면 되며 기본 값은 0으로 자동 삭제 기능을 이용하지 않게 된다.
기타
innodb_print_all_deadlocks=0 or 1 (기본 값: 0)
MariaDB에서 데드락에 대한 정보는 SHOW ENGINES INNODB STATUS 명령으로 확인할 수 있는데 이것은 마지막 데드락에 대한 정보만 보관하기 때문에 이전에 발생했던 데드락 정보는 확인할 수 없다. 이 파라미터를 1로 하면 모든 데드락 내용을 에러 로그파일에 기록한다.
커넥션
thread_handling=’one-thread-per-connection’ or ‘no-threads’ or ‘pool-of-threads’ (기본 값: one-thread-per-connection)
mariaDB에서는 쓰레드 풀을 사용할 수 있다. 이 파라미터의 값을 pool-of-threads로 하면 쓰레드 풀 기능을 사용하며 기본 값으로 두면 커넥션 당 하나씩 쓰레드를 제공하게 된다.
thread_pool_min_threads=1~ (기본 값: 1)
쓰레드 풀에 존재할 최소한의 쓰레드. 윈도우 전용의 파라미터이다.
thread_handling 파라미터가 pool-of-threads로 설정되었을 때 작동한다.
thread_pool_max_threads=1~65536 (기본 값: 1000)
쓰레드 풀이 이 파라미터의 값에 도달하면 더 이상 접속을 할 수 없게 된다. 이런 비상상황에서 관리자가 접근할 수 있도록 별도의 port를 만들 수 있으며 port 번호는 extra_port 파라미터로 지정한다.
thread_handling 파라미터가 pool-of-threads로 설정되었을 때 작동한다.
thread_pool_size=1~64 (기본 값: 장착된 core의 개수)
얼마나 많은 작업을 동시에 처리할 수 있는지에 대한 파라미터이다. 보통 Core 당 하나씩의 쓰레드가 돌아갈 때 최적의 성능을 낼 수 있으므로 장착된 Core 개수대로 설정한다.
thread_handling 파라미터가 pool-of-threads로 설정되었을 때 작동한다.
thread_pool_stall_limit=4~600 (기본 값: 500)
스레드 풀에 스레드가 하나도 남지 않았을 때 얼마나 더 기다렸다가 새로운 스레드를 생성할지를 결정하는 변수로 밀리 세컨드 단위로 값을 지정한다. 이 값이 너무 작으면 스레드 풀 자체의 효과가 줄어들고, 너무 크면 사용자가 커넥션을 맺기 위해 대기해야 하는 시간이 늘어나게 된다.
thread_handling 파라미터가 pool-of-threads로 설정되었을 때 작동한다.
thread_pool_idle_timeout= (기본 값: 60)
thread_pool_stall_limit 파라미터와는 반대로 유휴 쓰레드가 있을 경우 얼마나 대기했다가 없앨 것인지를 결정하는 파라미터이다. 단위는 초 이며 윈도우에는 없는 UNIX계열 전용의 파라미터이다.
thread_handling 파라미터가 pool-of-threads로 설정되었을 때 작동한다.
extra_port= (기본 값: 0)
쓰레드가 꽉 차서 추가로 커넥션을 만들 수 없을 경우를 대비하여, 관리자용 접속포트를 별도로 둘 수 있는 파라미터이다. 0이면 별도 포트를 두지 않는 것이며, 입력한 값에 대해 포트가 생성된다.
extra_max_connections= 1~100000(기본 값: 1)
extra_port 에 대해 설정된 포트에 최대 몇 개의 커넥션을 허용할 것인지를 결정하는 파라미터이다. 관리자용 포트는 기본적으로 커넥션마다 쓰레드가 생성되는 방식으로, 이 파라미터에 의해 결정된 값 만큼 쓰레드가 생성된다



